Tutorial: iterating ChatGPT, Claude, or Gemini against a deterministic oracle
This is the practical companion to the bring-your-own-AI argument: a start-to-finish walkthrough of authoring a Topolog plan with a model you already pay for. The workflow looks almost too simple to be a workflow, and that is the point: it is the compiler loop every programmer already knows, applied to plans. Model drafts, validator judges, errors go back, repeat.
You need a chat window with a capable model, the TOL handbook (one markdown file, downloadable from the handbook page), and a Topolog workspace with the Source tab open.
Step 1: brief the model#
Paste or attach the handbook and give the model a brief that supplies what only you know: the goal, the constraints, the failure modes. A shape that works well:
Read the attached TOL handbook. Write a complete TOL plan for: launching a paid online course by mid September. Constraints: one person (me), about 15 hours a week, 2,000 GBP budget for tooling and promotion. The course can fail review on the platform; model that. Use realistic estimates with cv values, milestones with dependencies, outcomes with priors, and sentinels for success, partial success, and failure. Return only the TOL source.
The specific phrases earn their place: "estimates with cv values" gets honest ranges instead of bare numbers, "outcomes with priors" forces the uncertainties into the open, and "sentinels for failure" makes the model admit the plan can end badly, which generic plan-generation prompts never do.
Step 2: paste and read the errors#
Copy the model's TOL into the Source tab. The validator runs as you paste, and a first attempt from a capable model typically lands with a handful of findings in the Problems drawer. Do not fix them by hand. Read them once (each names a rule, a location, and what is wrong), then select them and hand them straight back:
The plan failed validation with these errors: [paste]. Fix them and return the full corrected source.
A flavour of what comes back on a first pass, and why the errors are good news:
| Finding | What the model did | What the error teaches it |
|---|---|---|
| Cycle named through three edges | "Revise" pointing back at "review" | Loops must be bounded iterations, not back edges |
| Non-exhaustive sentinel gates | Modelled approval = true, forgot the else | Every fork needs somewhere for every future to land |
| Missing prior on a consumed outcome | Gated on an outcome it never gave odds | No probability, no forecast: the engine will not guess |
| Orphan task | A nice-to-have floating unconnected | Work must reach an ending or it is not in the plan |
Step 3: converge#
Paste the corrected source; if findings remain, loop again. In practice this converges fast (often one round, rarely more than three) and it converges for a structural reason worth understanding: fixing named, located errors in a spec-documented language is the task profile LLMs are best at, while the part they are weak at (global structural consistency over a 300-line artefact) is exactly what the validator carries. The loop pairs each system with its strength. It is the same division of labour the product's own builders use internally (the architecture of that boundary); you are simply driving it by hand with your own model.
Zero errors is a real threshold, not a vibe: the moment the drawer clears, the plan is structurally sound by the same eighty invariants any plan must pass, and the full instrument panel lights up: completion spectrum, schedule against your painted week, critical paths, the lot.
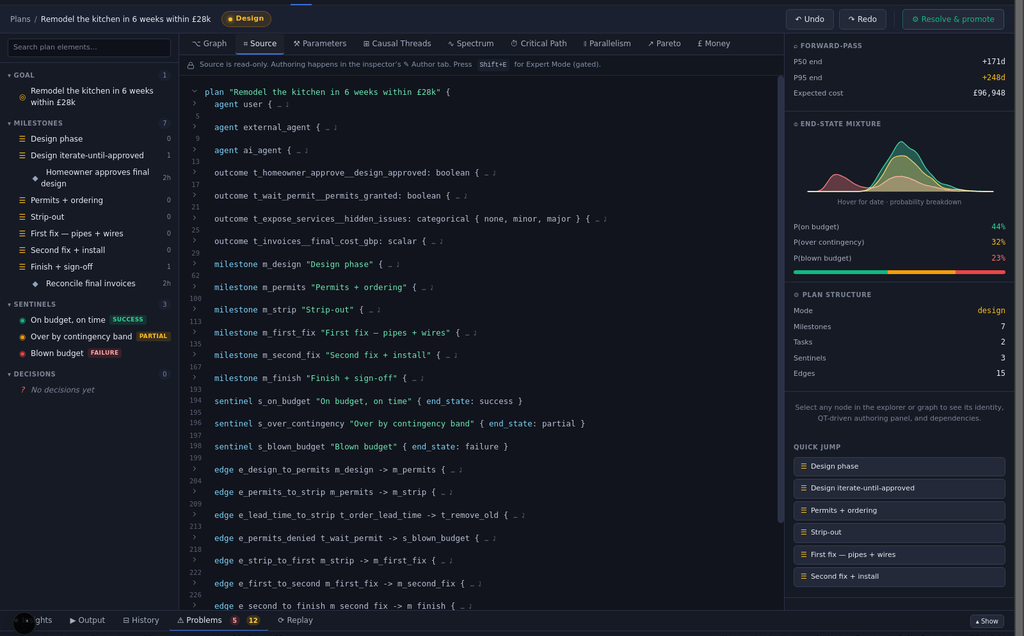
Step 4: make the judgement calls yours#
The validator certifies structure, not wisdom. Two questions remain genuinely yours. Are the estimates and spreads believable, or fluent-sounding defaults? (Re-anchor the few you have history on; let actuals recalibrate the rest.) And are the priors your odds or the model's optimism? The 0.7 on passing platform review is a judgement about your course, your platform, your draft. Eyeball the graph for the shape only you can check (the dependency the model could not know about), nudge, and watch the forecast respond.
Total cost of the exercise: one chat session on a subscription you already have, zero Topolog AI credits, and a validated probabilistic plan in roughly the time a kanban board would have taken to half-fill. The deeper takeaway travels beyond this product: generative tools become trustworthy exactly when something deterministic stands behind them. Find the oracle, close the loop, and the model you already pay for is suddenly worth a great deal more.